Machine Learning to Predict Socio-Economic Data
Iacopo Testi is an italian urban technologist and data scientist. His professional and academic interests revolve around the development and applications of data science methodologies to transform urban environments into sustainable and seanseable cities.
Today big data play a fundamental role in the deeper understanding of our urban areas. Nevertheless, collecting high resolution socio-economic information is still a challenging task for many countries and municipalities. In this article it is presented a short summary of the research [1], conducted by MIT Senseable City Lab and MIT China Future City Lab, that aims at predicting granular socioeconomic attributes based on restaurants data.
Detailed socio-economic data are critical for researchers and city managers in order to tailor policies that address specific needs. However, surveys or census are costly in terms of both economic resources and time. Therefore, the study proposes machine learning algorithms to foresee daytime and nighttime population, number of companies and spending levels, at different spatial resolutions, of nine Chinese cities.
The input sources used for the entire investigation are multiple [2]. Restaurant data are collected from dianping.com (2017-2018). Extracted features included name, longitude, latitude, cuisine category, price, taste rating and others. Daytime and nighttime population are estimated by mobile phone locations (2015). Companies data are retrieved from the registry database of the State Administration for Industry and Commercial Bureau of China (2000-2017). Consumption habits were gathered by the bank card records for point of sales (2016).
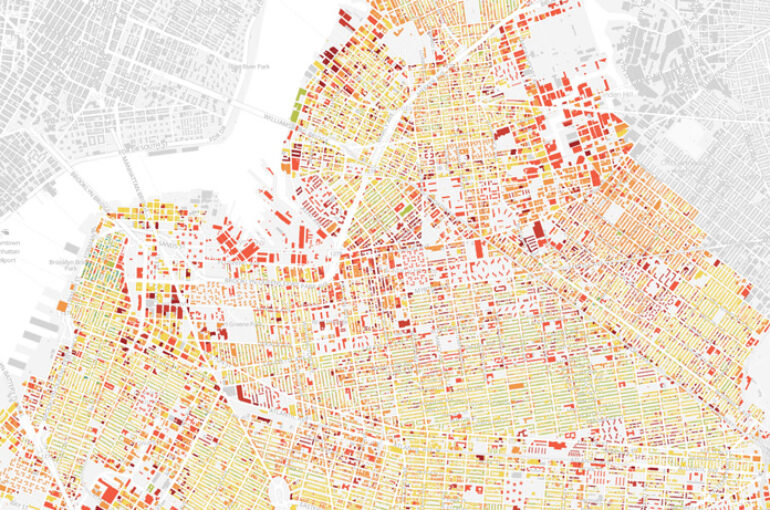
All data aforementioned where then aggregated within various spatial resolutions (from 1km to 5km square grids) for each city [3]. Furthermore , to predict the grid cell level socio-economic outcomes, MIT researchers applied the least absolute shrinkage and selector operator regression (Lasso), using cross validation to control the penalty of the model [4]. In fact, Lasso regression is simply the sum of the square residuals added to a penalty, which manages the trade between bias and variance. Therefore, increasing the fitting capability of the model on testing dataset.
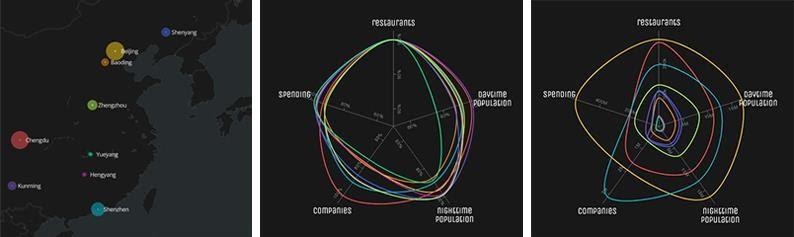
The picture above displays the prediction accuracy of daytime and nighttime population, number of companies and volume of consumption across the nine cities selected. As clear, the model used by the researches is strongly predictive of all variables of interest. Furthermore, the highest accuracy it is achieved by the population outcome which is assumed as proxies for employment and residents.
The entire research plainly reveals how machine learning has potentials to support city governors and decision makers. Specifically, monitor city performance in a timely, low-cost manner and allocating efficiently public resources. Concluding, if we only think about all our daily digital traces we can easily realize the incredible potentials of artificial intelligence methodologies applied to the urban planning domain.
References
[1] Lei Dong, Carlo Ratti, Siqi Zheng (2019) Predicting neighborhoods socioeconomic attributes using restaurant data. Senseable City Lab, Massachusetts Institute of Technology. Retrieved from http://senseable.mit.edu/papers/pdf/20190715_Dong-etal_PredictingRestaurant_PNAS.pdf[2] Lei Dong (2019) Repository restaurant data dianping. Retrieved from https://github.com/leiii/restaurant
[3] Lei Dong, Carlo Ratti, Siqi Zheng (2019) Predicting neighborhoods socioeconomic attributes using restaurant data. Senseable City Lab, Massachusetts Institute of Technology, Appendix, pp.3. Retrieved from https://www.pnas.org/content/pnas/suppl/2019/07/09/1903064116.DCSupplemental/pnas.1903064116.sapp .pdf
[4] ibshirani R (1996) Regression shrinkage and selection via the lasso.J Roy Stat Soc B Met58(1):267–288. Retrieved from
